Need fast iterations with hot reload, debugging, and collaboration over k8s envs?

There are several big decisions to make when starting a new software project. The choices you make around the programming language(s), framework(s), and source control structure are critical and will affect the way you work for years to come. Choosing wisely, in a way that reflects your organization culture, will save immense amounts of time and frustration down the road.
While the language you choose and the frameworks you rely on are heavily influenced by the team, domain, and product, the choice to use a mono or multi repo setup is not so clear-cut. There are many factors that can be more or less important for different teams, and even for different projects in the same organization.
At Raftt we are in a unique position to see *many* companies development setup, hear about their pains (and solve some of them!). We’ve seen a *huge* range of R&D department size, company maturity, and tech stacks. All the challenges below are things we’ve seen ourselves or at customers.
Before diving into the specifics, let’s be clear on some definitions:
**Monolithic architecture:** Architecting the company’s product as a single service.
**Microservices:** Architecting the company’s product as a number (potentially many) services deployed independently. An underlying assumption we have is that you are using micro-services at least in some part of your product. A purely monolithic approach has nothing to gain from using more than one repository for source control.
**Monorepo:** Having a single repository containing all of the company’s code.
**Multi-repo:** Having multiple repositories, each containing the code for some part of the company’s product.
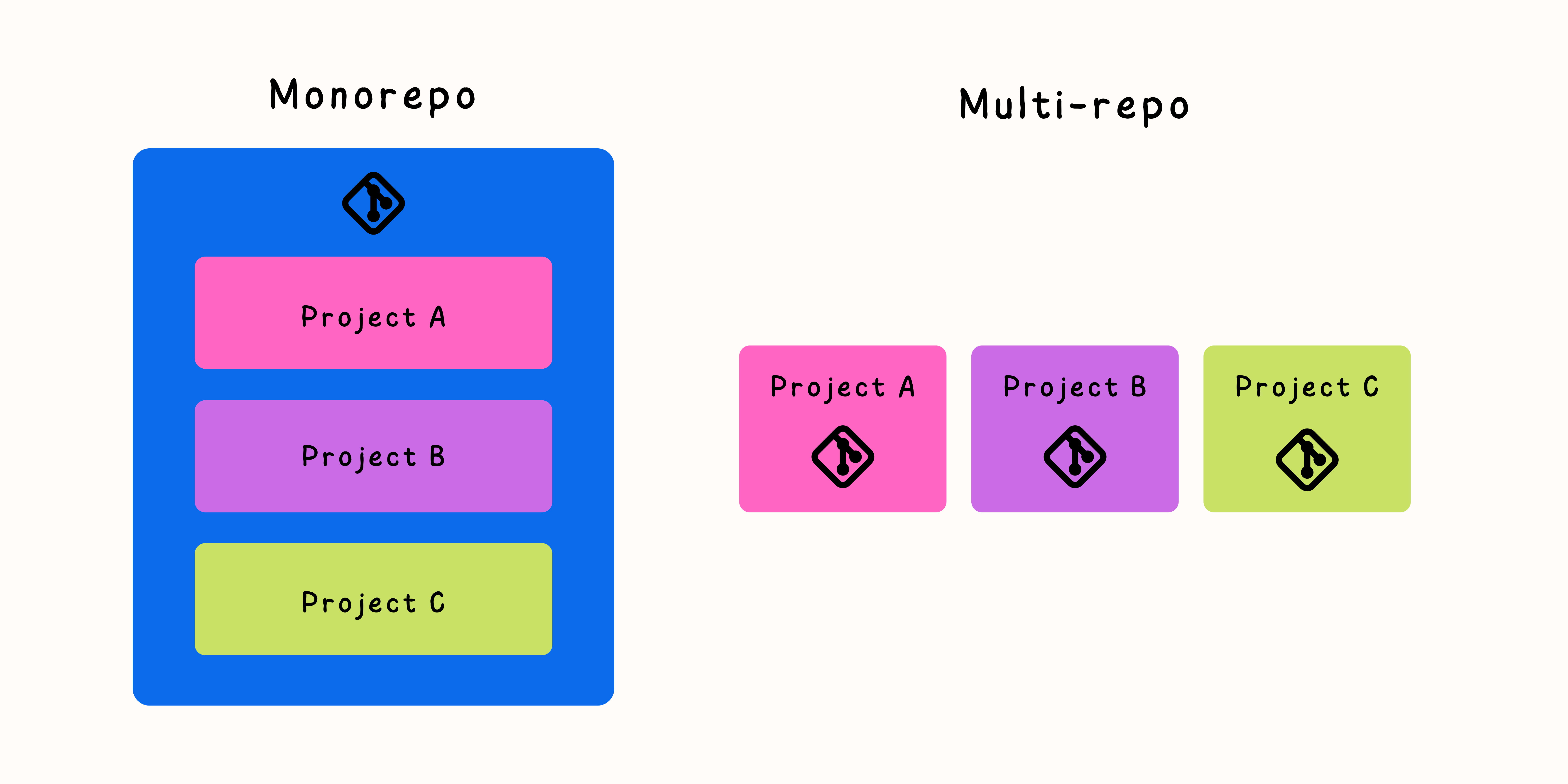
Of course, [almost] nothing is absolute - in most instances even if people have chosen to work with a monorepo, they will have additional repositories for forked open source projects, side projects, legacy, or for many other reasons. Same goes for Monolithic architecture, etc.
## Challenges when Working with Monorepos
There can be significant challenges when working with monorepos. We discuss the most significant of these below.
### Feature Branches Can Get Out of Control
Monorepos, where multiple teams work on various application parts, aren’t suited for long-lived feature branches; keeping them up to date becomes more challenging over time, and merge conflicts get out of hand quickly.
Instead, teams often use trunk-based development with feature flags. This increases visibility to the in-progress code, and reduces the chance for significant changes to be hidden from other developers. Since smaller portions of code are merged as they are written, there is a much lower likelihood for difficult merge conflicts.
### Big Repositories Slow Down Version Control
Depending on the size of your repository, the underlying source control system (Git unless you are really unique!), may start struggling to keep up. This translates to longer times cloning, pulling, checking out branches, which directly slows down the team, but can also be an exacerbating factor - long rebase times, for example, means people rebase less, which means harder merge conflicts, which leads to even more frustration.
Using git-lfs (large file storage) can help to minimize large files in the repo, and things like shallow clones and sparse checkouts can help with reducing the size of the Git history or the working tree. All of these have their own pros and cons.
While the multi-repo approach can suffer from this as well, it tends to be much more manageable.
### Your CI/CD Setup Can Be Complex
Most of the modern CI systems are **very** easy to set up and use, and this makes getting up and running with great tooling quite fast. The more complexity there is in the repository contents, the harder it is to adapt them to do what you need. With a monorepo, by default, you may end up building and testing **all** the projects in the repo, potentially taking an exorbitant amount of time.
Building, testing or deploying only part of the repository’s contents can require very specific configuration, which can be breakable and requires maintenance. At Raftt we took the time to create internal infrastructure that traverses the Golang package dependencies to figure out if a certain package should be built. This took some time, but was definitely worth it, as it was a significant time and signal improvement for our CI process.
### Versioning Can Get Cumbersome
Versioning the software project outputs does not have to be directly related to the source control structure, but it can be very convenient if it is. Using Git tags and/or branches on a monorepo means you either have many release branches and tags, or few that cover multiple projects.
Having many branches and tags is dangerous, because it can be difficult to track their state. For example, if you have an urgent fix that affects several of them, it can be hard to make sure to apply it everywhere.
Conversely, using just one tag might mean needlessly updating projects that might not have significant changes. Investing in your infrastructure to make the deployment process easy (and occurring often) can make this a non-issue, or even a benefit - you can be sure that all your services at the same version work together.
### Access Control Needs Additional Considerations
Using a monorepo can make it difficult to apply fine-grained permissions to your code. It is likely technically impossible to block **read** access to the entire repo to anyone that needs some part of it. Depending on your sensitivity to your company’s IP, this may be a critical factor.
You can definitely use directory or file-based permissions to affect **write** access, but this might require custom tooling, and will take some additional maintenance.
### DevTools and Services Can Have Problems with Monorepos
There are thousands of developer tools in common use. Many of them have certain assumptions on the structure of your source control, and those tend to assume that one project == one repository. This could be because they place certain files in the root of the repository, or because they make calls to Git themselves. Often this can be worked around, but might take some more work.
From a strategic perspective, following a monorepo approach means the company has to invest in adapting tooling to better support monorepos. Occasionally these adaptations can be difficult - for example, they could require forking open source projects, which adds another thing you or your team needs to maintain.
## Challenges when Working with Multi-repos
… but the grass isn’t always greener on the other side.
### Dependency Management Can Get Difficult
By placing separate modules, projects or services which depend on each other in different repositories, we introduce an added layer of complexity in dealing with them as a whole. Developers have to clone multiple repositories, and keep them all synced. If a module is used across multiple repositories, it can be hard to make sure a change to it doesn’t break any of them, both locally and in CI, as it requires triggering CI runs for dependent repositories.
### Code Duplication Happens More Often
A huge problem in software development is code duplication. Every copy of a function needs to be maintained, and worse - the discrepancies between them could be the cause of hard-to-find bugs.
When using a multi-repo approach, the chances are much higher that this will happen. Not only does the IDE see only part of the code at each time (so it is harder to find usages, search for similar methods, etc.), but it might be actually impossible to call code from another repository.
Some companies work around this by having a shared package in yet another repository which is loaded everywhere - this can cause that module to become bloated with code that is used in a bunch of different places, causing the exact mess that the multi-repo structure intends to solve.
### Changes Can Span Multiple Repositories
Small changes may be possible to complete within the bounds of a single repository. The larger the feature is, the more likely you will need to touch multiple repositories in order to solve it. This can be difficult - the IDE can’t help with finding the places you need to modify, so it may end up taking many roundtrips through the CI pipeline.
Even after modifying all the repositories as needed, you may encounter an atomic modification problem - it is impossible to guarantee committing to all repositories at the same time, so you can end up with a situation where some partial set of changes has been committed, but others are stuck. This could be due to CI issues, merge conflicts, or any other problem.
### Versioning and Dependency Management Can Become Complex
Unsurprisingly, versioning is still hard :). If you have different versions for each component, managing which versions work with which is a difficult manual task. If you have a single global version, how do you synchronize it between all the repositories?
### Separation of Concerns Can Fail
A fundamental concept of software development is the separation of concerns.
This concept often gets interpreted in two ways:
- **Separation of technical concerns.** For example, an encryption library should get its own repository because it’s responsible for just one technical aspect of the entire system.
- **Separation of features.** All code related to one feature should go into the same repository. For example, an authentication feature might consist of UI code and cryptographic code, but both work together so they will be co-located.
A multi-repo approach often forces separating one, leading to duplication or difficulty in separation with regards to the other. For example, if I have an auth service including it’s own UX and authentication libraries, reusing them in another service in another repository can require additional effort.
### End to End Tests in CI are Hard to Get Right
While unit and integration tests for specific services or projects may be much easier to set up, running end-to-end tests can be hard - they require the output from all of the repositories, so all the stages of the test require additional setup and maintenance -
- Triggering the End to End test from changes from multiple repositories requires either duplicated configuration between them, or an external service that handles them. Either way, additional complexity.
- Running the End to End test requires a context disconnected from all the other repos in which the test itself runs. This can be yet another repo, or an external service.
- Figuring out the blame for a particular test run that failed is hard - it could be a change from any of the repositories involved, and there isn’t a clear way to bisect to the right commit.
## Conclusion
At the most basic level, the choice between source control structures is a cultural one. Is it more important to isolate the behavior of a single component or to be able to influence the entire system at once? Are we open to investing in tooling as needed to support our developers or do we prefer using existing (often excellent) tools?
At [Raftt](https://www.raftt.io/), the ability of an engineer to make changes to any part of the stack was the critical factor in choosing to use a monorepo structure. We also enjoy the simplified version management, and the ease of creating deployment infrastructure that manages various parts of our product in one place, sharing as much code as possible.
The most significant challenge we encountered (and are still facing, really) is around CI/CD tooling. We have invested time into creating a system that adapts to changes in different components in the repository, using Golang-specific tooling that checks for a given target’s dependencies.
Some of our less-central projects are in separate repositories, often because they are forked from open source projects. In these we encounter a lot of the difficulties referenced in the multi-repo challenges.
.svg)
Stop wasting time worrying about your dev env.
Concentrate on your code.
The ability to focus on doing what you love best can be more than a bottled-up desire lost in a sea of frustration. Make it a reality — with Raftt.


